
EBSILON®Professional Online Dokumentation



Zur Konfiguration von EbsIdent wird der Menübefehl ”RechnenàEbsIdent konfigurieren...” verwendet. Mit diesem Befehl wird das EbsIdent - Konfigurationsfenster geöffnet.
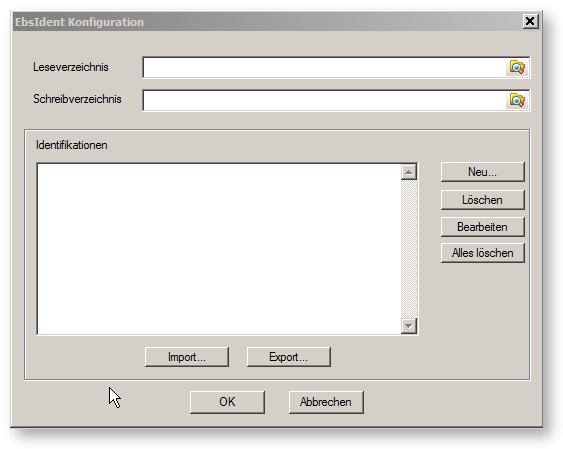
Zunächst sind zwei Verzeichnisse vorzugeben, nämlich ein Leseverzeichnis und ein Schreibverzeichnis.
Das Schreibverzeichnis wird für den Identifikationsprozess verwendet. Während die Identifikation läuft, schreibt EbsIdent verschiedene Daten in Dateien, die in diesem Verzeichnis liegen. Für jede zu identifizierende Größe (jede ”Identifikationsgröße”), verwendet EbsIdent drei Dateien. Alle drei tragen denselben Namen wie die zugehörige Identifikationsgröße, mit unterschiedlichen Erweiterungen:
die ”.bel”-Datei wird nur zur internen Datensammlung verwendet. Es handelt sich um eine Binärdatei.
die ”.ref”-Datei enthält die aktuellen Ergebnisse der Identifikation (Referenzpolynom) und Verwaltungsinformationen über den Status und den Gültigkeitsbereich der Identifikation. Es handelt sich ebenfalls um eine Binärdatei.
die ”.log”-Datei enthält in lesbarer Form (ASCII) wichtige Informationen über den Ablauf des Identifikationsprozesses. Insbesondere enthält sie das berechnete Referenzpolynom in lesbarer Form. Man muss deshalb auf diese Datei zurückgreifen, wenn man das Polynom als Anpassungspolynom für die Berechnung der Komponenten oder innerhalb von EbsScript verwenden will.
Das Leseverzeichnis wird zur Berechnung von Gütegraden verwendet. Wenn es mit dem Schreibverzeichnis übereinstimmt, beruht die Berechnung der Gütegrade stets auf dem aktuellen Stand der Identifikation. Man kann jedoch auch ein anderes Verzeichnis angeben, wenn die Identifikation abgeschlossen wurde, und mit dieser Identifikation die Gütegrade bestimmen, während man im Hintergrund bereits eine neue Identifikation durchführt.
Im allgemeinen ist die Identifikation Bestandteil einer Schaltung. Es ist allerdings möglich, die eingegebenen Formeln zwischen verschiedenen Schaltungen zu übertragen, wenn man die Export/Import-Funktionalität verwendet.
Mit dem ”Export” Knopf erstellt man eine Textdatei, die alle Informationen über die spezifizierten Identifikationseinträge enthält. Sie enthält jedoch keine gesammelten oder berechneten Daten.
Mit dem ”Import” Knopf liest man eine Datei ein, die zuvor mit ”Export” (oder manuell mit einem Editor) erstellt wurde. Die Identifikationseinträge werden dann zu denen hinzugefügt, die bereits in der Schaltung vorhanden sind. Es ist deshalb möglich, Identifikationseinträge aus verschiedenen Schaltungen zu importieren. In diesem Fall ist zu beachten, dass sich die ID-Nummern der Identifikationseinträge ändern können und man deshalb in den Aufrufen der Funktion ”qualityFactors” im EbsScript eine Anpassung vornehmen muss.
Der ”Neu” Knopf wird verwendet, um eine neue Identifikationsgröße anzulegen. Es wird das Dialogfenster ”EbsIdent Identifikationsgröße” aufgeschaltet.
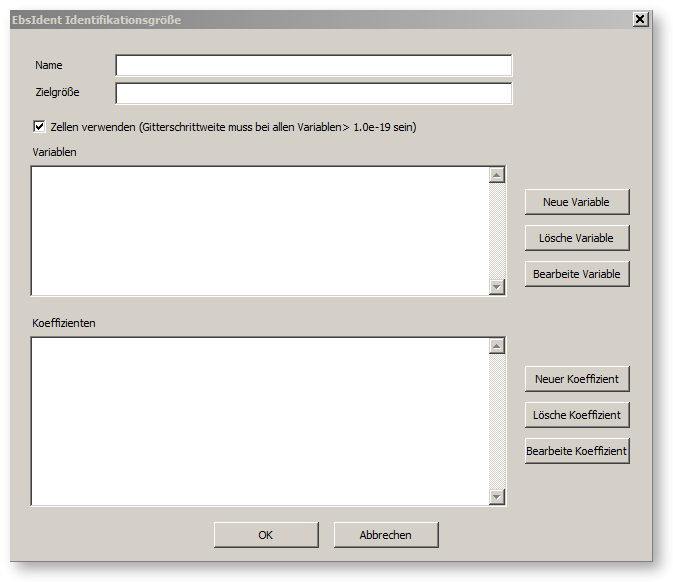
Bitte Checkbox "Zellen verwenden" beachten (siehe dazu EbsIdent -temporäre Identifikation)
In diesem Dialog wird zunächst der Name und die Zielgröße angegeben. Der Name ist beliebig, wird aber in den abgelegten Daten im Dateinamen verwendet. Dies ist zu beachten, wenn man einen Eintrag umbenennt oder einen bereits verwendeten Namen wiederverwendet. Im Feld Zielgröße wird die Zielgröße für die Identifikation in EbsScript - Schreibweise eingetragen. Im genannten Beispiel war dies die Temperatur auf der Leitung A, ”A.T”. Anstelle eines einfachen Ausdrucks kann hier auch eine Formel eingetragen werden.
Das Feld ”Variable” muss über den Knopf ”Neue Variable” gefüllt werden. Wenn man auf diesen Knopf klickt, erscheint das Dialogfenster ”EbsIdent Variable”.
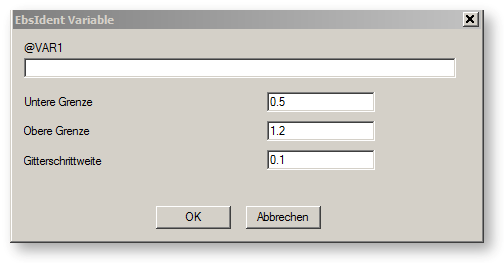
Hier muss der Ausdruck für die Variable in EbsScript - Schreibweise angegeben werden. In unserem Beispiel waren dies die beiden Variablen ”B.P” und ”C.M”. Für jede Variable werden außerdem Bereichsinformationen erwartet. Dies ist für den Datensammlungsprozess während der Identifikationsphase wichtig. Die Felder ”Untere Grenze” und ”Obere Grenze” geben den relevanten Bereich für diese Variable an. Es werden bei der Identifikation nur die Datensätze verarbeitet, bei denen alle Variablen zwischen ihrer unteren und oberen Grenze liegen. Wenn eine Variable außerhalb dieses Bereichs liegt, wird der entsprechende Datensatz nicht berücksichtigt (dies wird allerdings in der Logdatei vermerkt). Die Gitterschrittweite bestimmt das Speicherverhalten des Datensammlungsprozesses. Je enger das Gitter, umso mehr Daten werden gesammelt.
Mit dem Knopf ”Bearbeite Variable” kann die entsprechende Variable nach ihrer Erstellung nochmals überarbeitet werden, allerdings nur solange der Identifikationsprozess noch nicht begonnen hat (Anmerkung siehe unten).
Mit dem Knopf ”Lösche Variable” wird ein Eintrag aus der Variablenliste gelöscht (es gibt hierfür übrigens keinen ”Rückgängig”-Knopf).
Das Feld ”Koeffizienten” im Fenster ”EbsIdent Identifikationsgröße” wird mit dem Knopf ”Neuer Koeffizient” gefüllt. Wenn man diesen Knopf betätigt, wird das Dialogfenster ”EbsIdent Formel” geöffnet.

In dieses Feld wird die Formel eingetragen, die festlegt, wie sich der entsprechende Koeffizient berechnet. Man kann dabei einen beliebigen EbsScript - Ausdruck eingeben. Außerdem kann man die Bezeichnung ”@VARn” verwenden, um einen Bezug zu der n-ten Variablen herzustellen, die zuvor definiert wurde.
Der Knopf ”Bearbeite Koeffizient” wird verwendet, um einen Koeffizienten zu korrigieren, nachdem er definiert wurde. Mit dem Knopf ”Lösche Koeffizient” wird ein Koeffizient gelöscht.
Achtung: Nachdem bereits ein Identifikationslauf durchgeführt wurde (d.h. die ”EbsIdent”-Funktion aufgerufen wurde), sollte man keine Änderungen mehr an der EbsIdent - Konfiguration vornehmen. Da EbsIdent-Zwischendaten in Dateien speichert, kann es zu Fehlinterpretationen kommen, wenn die Daten nicht mehr zueinander passen. Wenn man nachträglich noch Änderungen der Konfiguration vornehmen will, sollte man zunächst alle angelegten EbsIdent - Dateien (”.bel”, ”.ref” und ”.log” Dateien) löschen. Nur wenn die entsprechenden Dateien nicht mehr da sind, startet EbsIdent die Identifikation komplett neu.
Die von EbsIdent benötigten Daten wurden stets in externen Dateien abgelegt. Es besteht auch die Möglichkeit, temporäre Identifikationen durchzuführen, bei denen alle Daten intern gehalten werden. Diese stehen allerdings nur solange zur Verfügung, wie Ebsilon geöffnet bleibt.
Die Checkbox „Zellen verwenden“ ermöglicht die Aktivierung bzw. Deaktivierung der Verwendung von Zellen bei der Datensammlung. Wenn keine Zellen verwendet werden, wird jeder Datensatz für die Identifikation verwendet. Andernfalls werden Datensätze verworfen, wenn die Maximalzahl pro Zelle erreicht ist. Dadurch wird sichergestellt, dass häufig vorkommende Betriebszustände nicht übermäßig starkes Gewicht erhalten.