
EBSILON®Professional Online Documentation



测量值会随机地相互依赖。协方差矩阵被用来定义测量值之间的相关性。相关系数被用作输入,取值在 -1 和 +1 之间。正值表示一个测量值的变化与另一个测量值的变化正向相关。负值表示。如果一个数值变小,另一个就会变大,反之亦然。
区分三种类型的相关关系很重要:
前两种类型的相关性都必须被指定(主要是由编程或建模)。模型产生的关联是校核计算的结果。
只有在测量值不是相互独立的情况下(例如,用相同的测量仪器),才需要考虑测量结果的明确关联性。随机偏差可能会叠加在这种相关性上,因此,相应地设置要输入的相关系必须小于 1。
隐性关联的产生是由于没有使用温度,而是用比热焓作为解决算法的变量。例如,如果一条管道上有一个压力和两个温度测量点,则使用相同的压力将温度转换为比焓。因此,压力测量的偏差对两个焓值有相同的影响,从而形成了隐性关联。隐性关联的一个特殊情况是由材料价值表中的不确定性导致的。在这里,根据 VDI 2048,表 1 的方程式 102,假设未知的系统偏差由于材料表的不确定性而产生,如果调用参数的值彼此接近,则是相互关联的。
第三种类型的计算值(校核的测量值和结果量)之间的相关性来自于模型中的连接,这导致了根据误差传播规律通过工艺过程方程组产生的耦合。例如在电厂中,给水量和发电机功率之间肯定存在关联,即使测量结果是完全相互独立的。
只有在按照 VDI 2048 进行计算时,才会考虑不同测量点之间的相关性。如果是简单的快速校核,只有协方差矩阵的对角线被填充(见校核方法)。建议在使用这种方法时,与根据 VDI 2048 的方法进行比较,以便清楚了解忽略相关性对结果的量化影响。还应该同时用 Chi^2 检验比率来检查加权情况。
相关性是通过"协方差矩阵"对话框输入的,该对话框可从菜单"计算" à "相关性"调用:
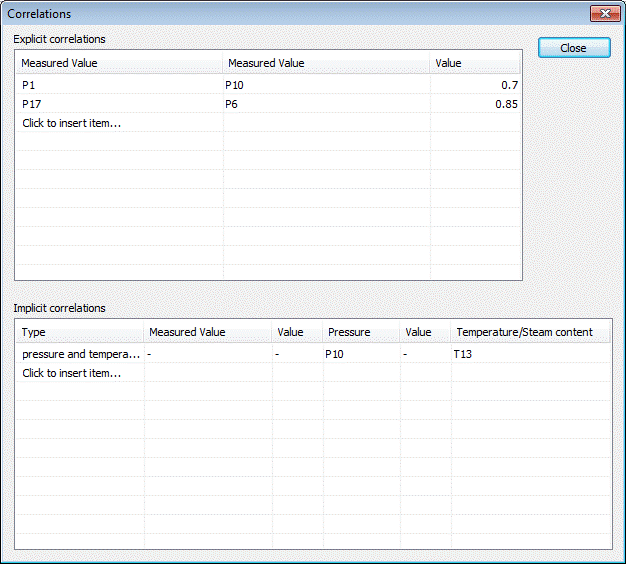
所有的相关性都可以在这些表中输入。点击"显性关联"表中的"点击插入..."字段,打开一个选择列表,显示模型的所有测量值,选择其中一个。在第二列中,选择一个与第一个相关的测量值。在第三列指定相关系数,必须在 -1.0 和 1.0 之间。协方差矩阵的对称填充通过编程实现。在计算过程中,确认符合 VDI 2048,表 1 的条件 105(矩阵半正定)。
隐性相关性可以在"隐性关联"表中插入。
点击相应的字段可修改一个相关关系。
要删除一个相关关系,可以点击相应行的任何位置来选定相应的条目,然后按"删除"键。
关闭这个对话框时,所有改变都保存在模型中,并在进行校核计算时应用。
隐性关联只能在温度和与其相关的压力测量点之间输入。如果两个温度测量点与同一个压力测量点相关,程序会自动考虑到两个相关的比焓的相关性。然而,这种机制只限于两个温度测量点。如果有两个以上的温度测量点与一个压力测量点相关联,可以按以下步骤进行:
对于隐性关联,输入的相关系数不起作用,因为相关系数在计算中自动确定。只要在校核参数中进行相应设置,计算也会自动考虑材料表的不确定性。但是,如果没有设置自动考虑材料表的不确定性,则使用此处输入的相关系数。
按照模型,相互连接的结果值(校核的测量值和其他结果量)相应地被关联起来。如果是一个有 500 条管道的模型,这将导致超过 100 万个相关系数。由于相关系数的绝对值有一个可预设的最小值,对于每个测量值来讲,只有那些相关系数绝对值超过指定最小值的相关测量值才被放在一起考虑。
根据 VDI 2048,表 1,公式141,这个列表也包含了各自的偏差判据,可以通过右键点击组件的测量值来调用(例如:改造实例中的最后一个列表"计算出的相关性改进")。在结果掩码(用鼠标左键选择)中,显示测量值的最强相关指数和自身偏差判据。
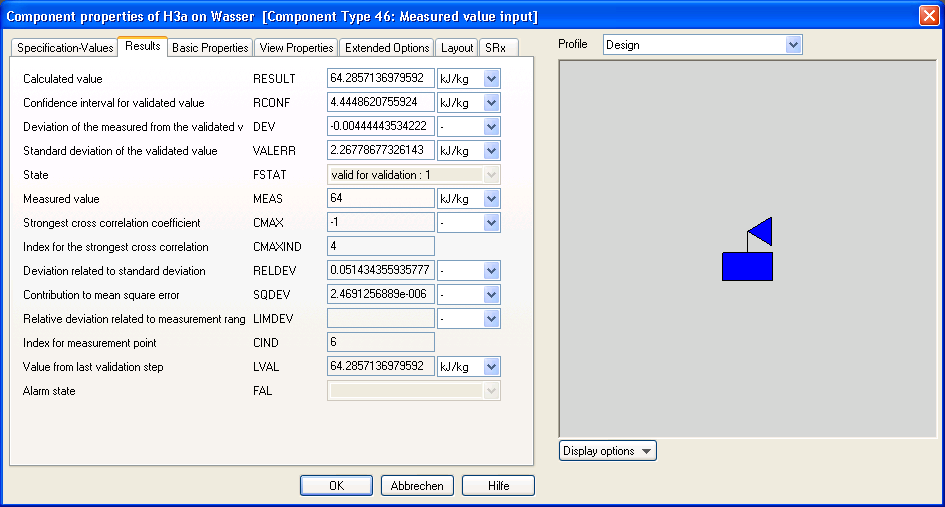
在校核计算之后,除了校核值之外,测量值掩码还包含其他计算量。校核计算调用情况将在下一节中描述,
根据 VDI 2048,表 1,方程式 129,值 CMAXIND 包含一个指数索引,指定存在最强相关性的测量点。相关性的值可以在 CMAX 下找到。CIND 是指测量点本身的指数索引。
图中,显示了带有指数索引 6 的测量点的结果。测量点 6 与测量点 4 的相关性最强,其相关系数为 -1。