
EBSILON®Professional Online Documentation



为了配置 EbsIdent 模块,使用菜单命令"计算 àEbsIdent 配置...",打开 EbsIdent 配置窗口:
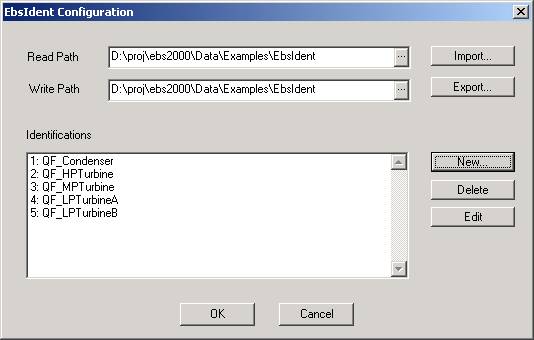
首先必须指定两个路径,即一个读取路径和一个写如路径。
写入路径用于识别过程。在识别过程中,EbsIdent 会将某些数据存储写入到该目录的文件中。对于每个识别项,EbsIdent 使用三个文件。所有文件都有识别项的名称,但有不同的扩展名:
读取路径用于计算质量系数。如果与写入路径相同,质量系数的计算就是基于识别的当前状态。如果已经有了一个完成的识别,并且想在后台进行新的识别的同时,使用这个识别来计算质量系数,就可以指定一个不同的路径来进行读取。
一般来说,识别是模型的一部分。通过使用"导出/导入"功能,可以在不同循环之间传递指定的公式。
通过"导出"按钮,可以创建一个文本文件,其中包含所指定识别条目的所有信息。注意,它不包含收集或计算的数据。
通过"导入"按钮,可以读取一个之前由"导出"(或用编辑器手动)编写的文本文件。这个文件中包含的识别条目被添加到模型中已有的条目中,从而可以实现从不同的模型导入识别条目。在这种情况下,应该注意的是,识别项的 ID 号码可以被改变,必须在 EbsScript 中调整对函数"qualityFactors"的调用。
"新建"按钮用于创建一个新的识别条目,打开对话窗口"EbsIdent 识别量"。
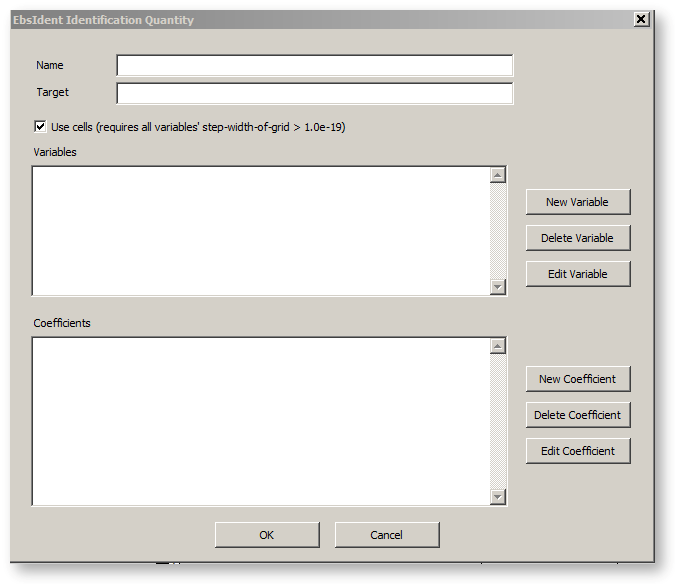
请勾选"使用单元格"复选框(见下文 "Ebsident - 临时识别")。
在这个对话框中,首先指定名称和目标尺寸。该名称是任意的,但将被用于存储数据的文件名中。在重新命名一个条目或重新使用一个已经使用过的名字时,应该考虑到这一点。识别的目标值在 EbsScript 符号指定的目标值字段中输入。在上面提到的例子中,管道 A 上的温度为"A.T"。在这里也可以指定一个公式,而不使用简单的表达式。
"变量"字段必须使用"新变量"按钮来填写。当点击这个按钮时,"EbsIdent 变量"对话框打开。
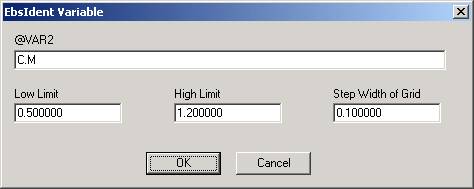
在这里,变量的表达式必须用 EbsScript 的符号给出。在例子中,这两个变量为"B.P"和"C.M"。对于每个变量,都需要有范围信息。这对识别阶段的数据收集过程很重要。字段"下限"和"上限"表示该变量的相关范围。只有当所有变量的值都在其下限和上限之间时,数据集才被考虑用于识别。如果一个变量超出其范围,相应的数据集就会被丢弃(日志文件中会有注明)。网格步长决定了数据收集过程的存储行为。网格越窄,收集的数据就越多。
只要还没有开始识别(见下文注释),可以通过"编辑变量"按钮,在创建后修改相应的变量。
"删除变量"按钮可以从变量列表中删除一个条目。注意,删除后不能"撤销"。
"EbsIdent 识别量"对话框中的"系数"字段必须通过"新系数"按钮填写。点击这个按钮,"EbsIdent 公式"对话框打开。

在这个输入框中,可以输入如何计算相应系数的公式。可以输入一个任何 EbsScript 表达式,此外还可以使用表达式"@VARn"用于创建对先前定义的第 n 个变量的引用。
"编辑系数"按钮用于修改创建后的系数,"删除系数"按钮用于删除一个系数条目。
注意:一旦执行识别运行后(即调用"EbsIdent"函数),就不应该对 EbsIdent 配置进行任何修改。由于 EbsIdent 将数据存储在中间文件中,如果某些数据不再匹配,可能会出现混乱。如果必须要修改配置,应该首先删除所有 EbsIdent 文件(".bel"、".ref "和".log "文件)。只有当相应的文件不再存在时,EbsIdent 才会完全重新启动识别。